The big data paradox

Service providers are filling big data lakes. Operations rely on analytics to make data driven decisions, so capturing any data that helps deliver better network performance, optimize resources and user experience is critical.
Data takes on another dimension in dynamic 5G cloud-native networks, high-quality, granular, real-time data and prescriptive analytics are essential for orchestration, automated problem detection, root cause analysis and delivering demanding new 5G services backed by stringent SLAs.
So it’s true: “data is the new oil”. In the context of telco big data, there are plenty of parallels.
Storing data is just like storing oil. It tends to be extracted from many places and stored in many repositories. A profusion of disconnected big data lakes is such a problem that operators are spending big money to make sure it doesn’t hold back 5G.
The market for unified data management solutions will top US$2B by 2024 (see Figure 1), at which point about half of the data required for 5G operations will be centralized, up from less than 5% today.
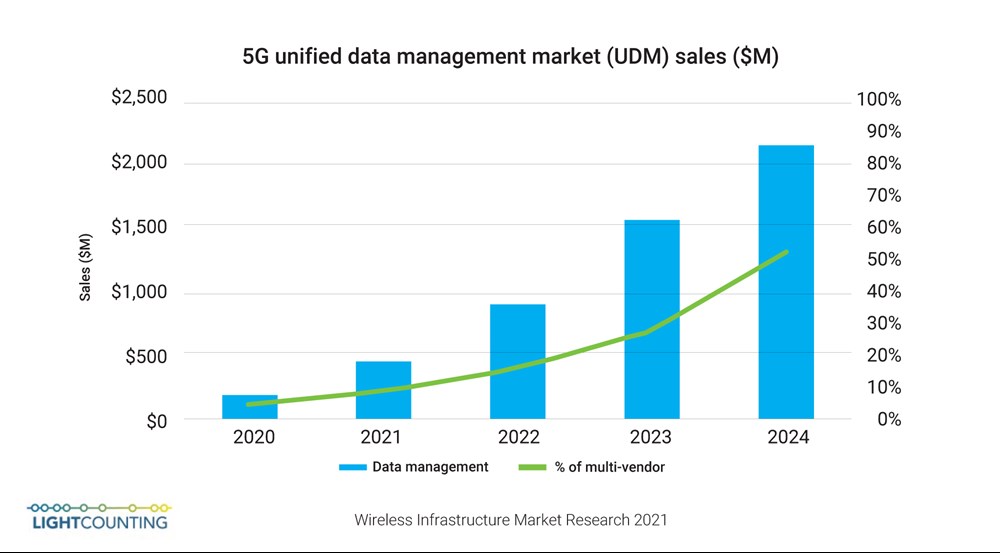
Figure 1: 5G Unified Data Management Market, report from Wireless Infrastructure Market Research 2021.
Pulling data together is a good start, but only solves part of the problem. Just like oil during the pandemic, we have much more supply than demand. Everyday tons of data that might be useful is stored without knowing exactly how it will be used. As IDC points out, less than 0.5% of big data gets analyzed*.
It’s good to save for a rainy day but saving data and saving money are not compatible.
That’s because just like oil, extracting, moving and storing data is expensive. In telco operations, it can be VERY big, and VERY expensive. It’s not a good idea to stockpile data “just in case” (see Figure 2).
Not only is big data expensive, it’s also slow. Real-time orchestration requires instant feedback to prescribe effective action. Running queries across big data takes too long.
This is the big data paradox.
You need it but can’t afford it. You need it now, but it arrives too late.
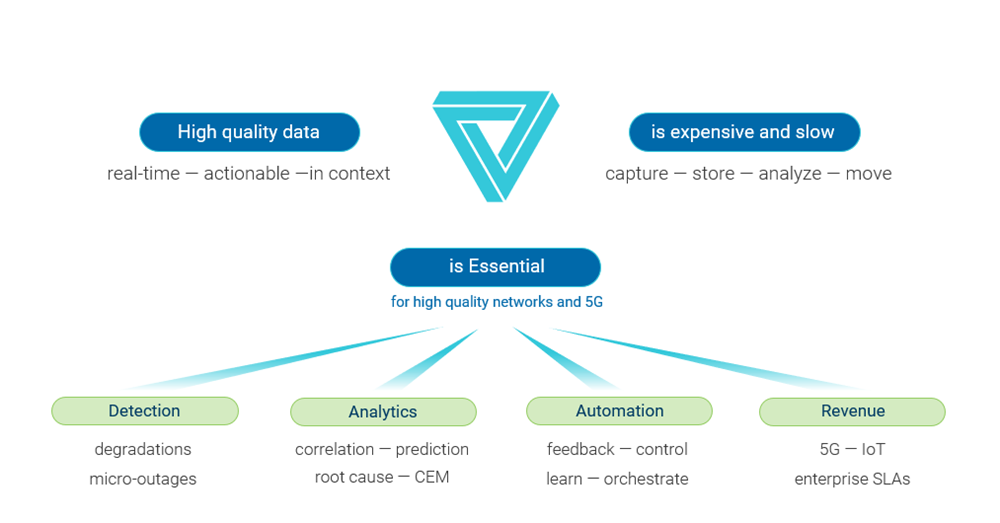
Figure 2: The big data paradox.
Like many data issues, fixing it at source is the best solution. Overcoming big data means going on a big data diet: data shouldn’t be consumed and stored if it doesn’t deliver insight. This is the ‘small data’ that enables 5G.
In service assurance fixing data ‘at source’ means carefully choosing what to measure, move and analyze. It means determining what’s valuable close to the source and discarding the rest. The goal is to keep the insight and supporting metrics in context, not all the ‘filler’ in between.
A combination of AI-driven, adaptive data capture and streaming analytics delivers just that: fast actionable insight that overcomes big data bloat and delays (see Figure 3).
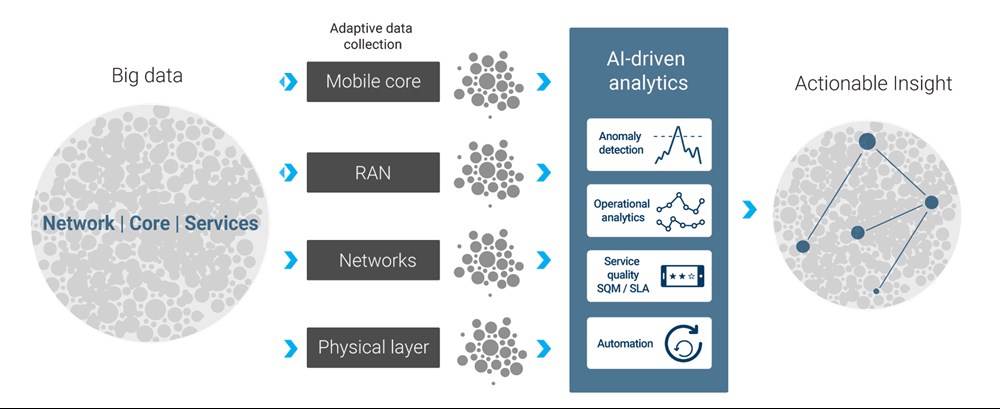
Figure 3: Moving from big data to actionable insight.
Consider the simple case of monitoring latency on a 5G backhaul link. It should be in spec 99.999% of the time. Storing all this ‘things are fine’ data would fill the data lake, without delivering any insight. No action would result. Nothing would be learned.
Instead, if only the 0.001% of data that means something was captured—when latency is out of spec—the cloud bill could be 100,000 times smaller, and insight could arrive that much faster. Think milliseconds instead of minutes.
Here’s an example of using AI-based anomaly detection to capture the right data at the right moment in time (see Figure 4). ‘Normal’ is determined by machine learning analyzing streaming data. Data never gets stored unless it’s useful.
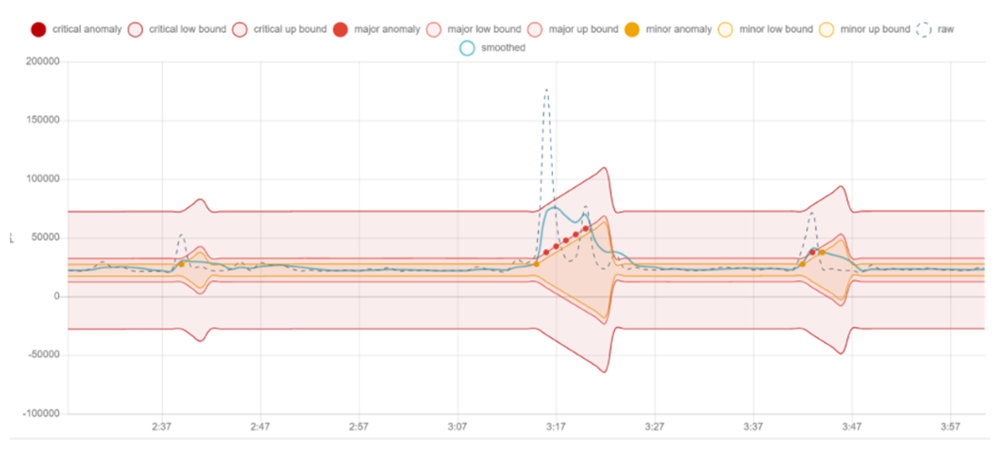
Figure 4: Example of AI-based anomaly detection.
The goal is to keep on the lookout for service impacting events but keep resource consumption and data to a minimum.
When you consider the thousands of metrics required to gain a complete view of network state, performance, quality of experience and SLA compliance, this approach doesn’t just keep data size and delays to a minimum. It also reduces the data that AI-driven analytics processes to correlate faults, assess impact, identify root cause and prescribe action.
AI detection and analytics are essential—but not sufficient—to optimize data speed and expense. Choosing carefully what to capture is important, but so is deciding how much, when, and where. Probes use compute resources. It’s best to keep them as small and local as possible.
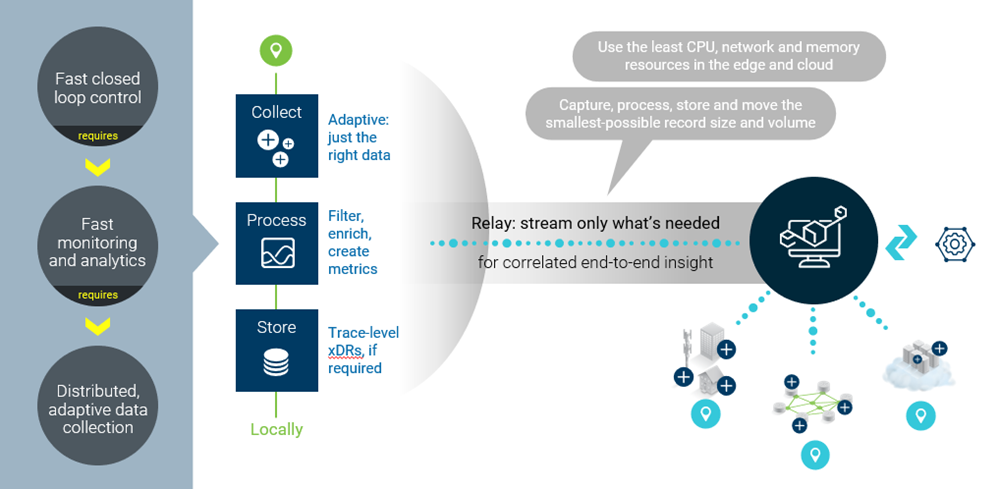
Figure 5: Adaptive data collection techniques.
Adaptive data collection techniques that instantiate probes, scale them up and down as needed, and dynamically adjust measurement depth and resolution are the best way to keep data volumes to a minimum while optimizing resource efficiency (see Figure 5).
Finally, distributing analytics close to data capture completes the ‘small data’ equation. Converting streams of data into usable metrics means massive volumes of raw data can be discarded instead of pulled across the network to centralized storage and analytics functions.
This distributed capture and analytics approach aligns with domain orchestration strategies that seek to identify and resolve problems as close to their origin as possible.
These small data essentials—AI-driven analytics, adaptive data collection and localized processing—are not conceptual.
They are real and effective. They are the natural evolution of probing and service assurance systems that also need to be as cloud-native, orchestrated and automated as the networks and services they will monitor.


