大数据的矛盾

运营商正在往大数据湖里填充数据。运营部门依靠分析功能来做出数据驱动的决策,因此抓取可帮助提升网络性能、优化资源与用户体验的数据非常关键。
数据在动态的5G云原生网络中会呈现出另一个维度——高质量、详细、实时的数据以及规范性分析对于进行编排、自动检测故障、分析根因和提供符合严格SLA要求的5G新服务至关重要。
所以,有句话说得对:“数据就是新的石油”。在电信大数据的背景下,二者有很多相似之处。
储存数据就像储存石油一样。数据往往从许多地方提取出来并储存在多个存储库中。目前有许多大数据湖互不相连,造成了非常严重的问题,以至于运营商不得不投入大笔资金,以确保它们不会阻碍5G的发展。
到2024年,一体化数据管理解决方案的市场规模将超过20亿美元(见图1),届时5G运营所需要的数据将有大约一半被集中存储,而目前这一比例还不到5%。
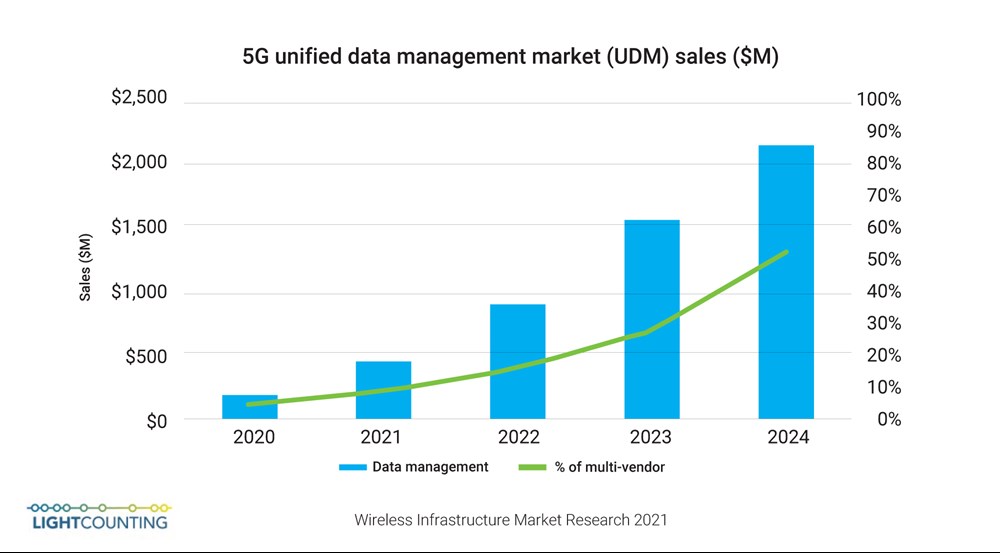
图1:一体化5G数据管理市场规模(来自《2021年无线基础设施市场研究报告》)。
将数据集中存储是一个良好的开端,但这只能解决部分问题。就像在疫情期间,石油的供给远大于需求。每天都有大量可能有用的数据被存储起来,但不知道具体该如何使用这些数据。IDC指出,最终被分析的大数据不到0.5%*。
未雨绸缪固然是件好事,但存储数据和存钱却并不是一回事。
这是因为就像石油一样,数据的提取、移动和存储成本都很高。在电信运营环境中,数据可能非常多,而相应的成本会很高。将数据存储起来“以防万一”并不是一个好主意(见图2)。
大数据不仅成本高,而且速度也很慢。实时编排需要有即时的反馈信息,才能规定有效的行动。而查询大数据会花费太长的时间。
这就是大数据的矛盾。
我们需要大数据,但又负担不起。我们现在就需要大数据,但它却姗姗来迟。
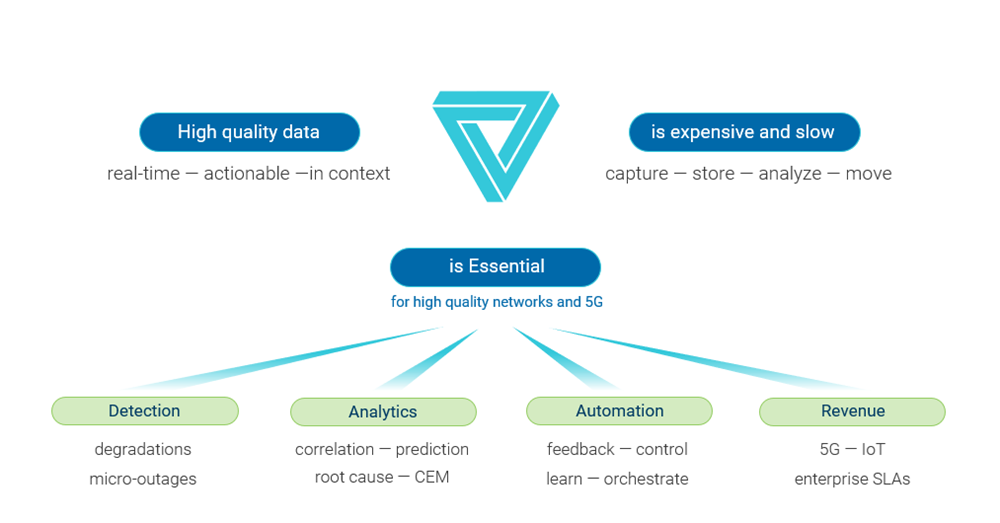
图2:大数据的矛盾。
和许多数据问题一样,最好的解决方法就是从源头解决问题。克服大数据的矛盾需要进行大数据节食:如果某些数据不能提供洞察力,就不应使用和储存它们。而被使用和储存起来的数据就是支持5G的“小数据”。
在服务保障中,要从“源头”解决数据问题,就必须仔细选择要测量、移动和分析的数据。这意味着在接近源头的地方确定哪些数据有价值,然后丢弃其余的数据。这么做的目的是仅保留并分析能够提供洞察力的指标,而不是关注那些无用的数据。
如果将AI驱动、自适应的数据抓取同数据流分析结合起来,就可以做到这一点:迅速提供可付诸实施的洞察力,克服大数据膨胀和延迟的问题呢(见图3)。
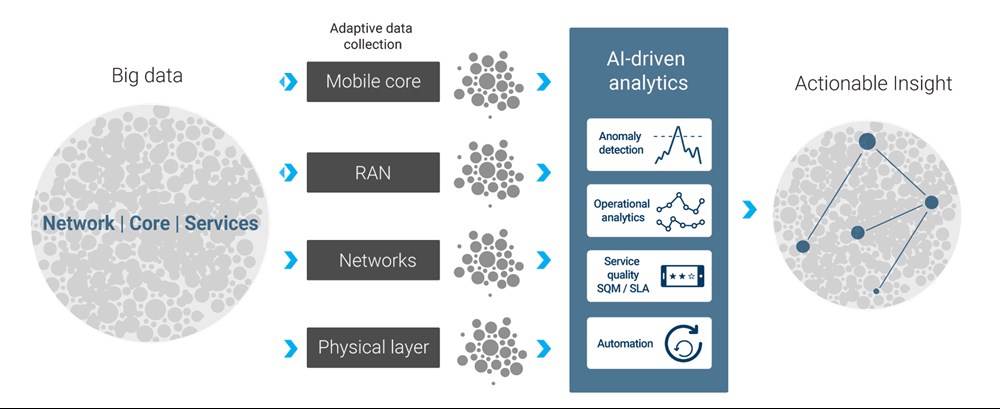
图3:从大数据转向可付诸实施的洞察力。
接下来我们可以考虑一个简单的情景——监测5G回传链路上的延迟。该延迟应该在99.999%的时间内都符合规范要求。如果将这些“显示一切正常”的所有数据都储存起来,将会填满数据湖,但不会提供任何洞察力。这些数据不会帮助我们采取任何措施。而我们也无法获得任何洞察力。
相反,如果只抓取那些重要的数据,这些数据占数据总量的0.001%——在延迟超出规范要求时——可以将云计算成本减少100,000倍,并更快地获取洞察力。延迟应该以毫秒而不是分钟计。
下面是一个使用基于AI的异常检测功能在适当的时间抓取适当数据的示例(见图4)。机器学习功能通过分析数据流,由此判定网络“正常”。除非数据有用,否则永远都不会储存数据。
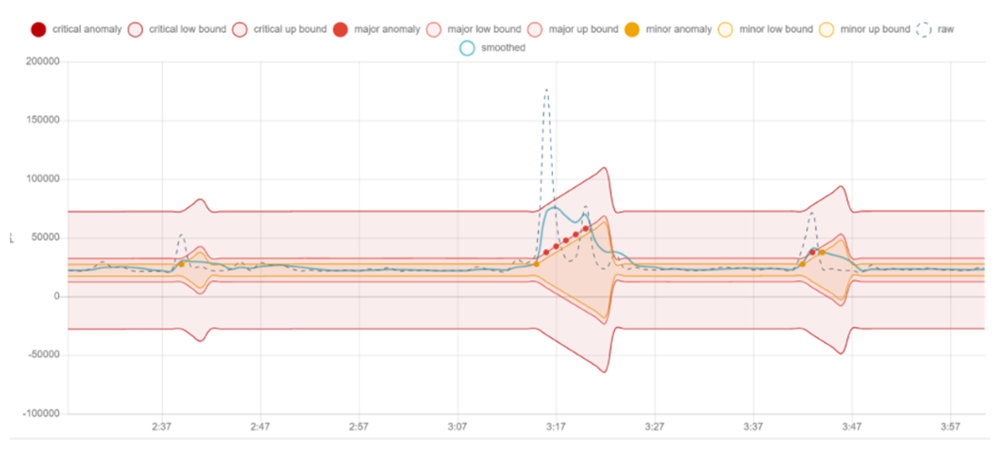
图4:基于AI的异常检测示例。
我们的目标是留心影响服务的事件,同时将资源消耗和数据量降到最低限度。
鉴于需要数千个指标才能完整地了解网络状态、性能、体验质量和SLA合规性,因此这种方法不仅将数据量和延迟保持在最低限度。它还可以减少AI驱动的分析功能所处理的数据,以便关联故障、评估影响、确定根因并规范行动。
AI检测和分析必不可少,但还不足以优化数据的处理速度和费用。仔细选择要抓取的数据很重要,但确定抓取数据的数量、时间和地点也很重要。探针会使用计算资源。因此,最好让它们尽可能小且本地化。
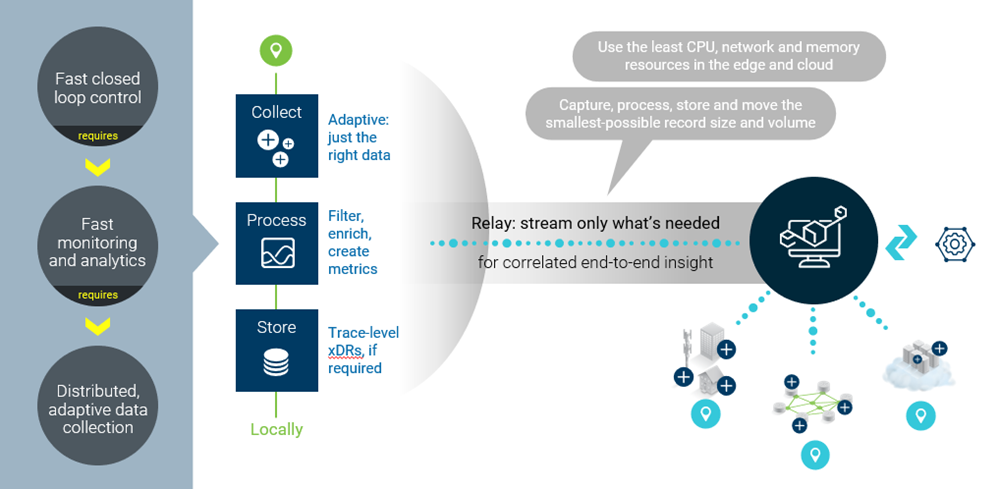
图5:自适应数据采集技术。
自适应数据采集技术将探针实例化,根据需要扩展或缩小探针,并动态地调整测量深度和分辨率,因此是在优化资源效率的同时将数据量降到最低的最佳方法(见图5)。
最后,在靠近抓取数据的地方进行分析可以减少传输不必要的原始数据,从而更快地提供洞察力。将数据流转换为可使用的指标意味着能够丢弃大量的原始数据,而不是在网络内集中储存和分析这些数据。
这种分布式抓取和分析数据的方法符合网域编排策略——尽可能靠近源头发现和解决问题。
有些对于小数据必不可少的要素——AI驱动的分析、自适应数据收集和本地化处理——不是抽象的概念。
相反,它们都真实有效。它们是检测和服务保障系统自然进化发展的结果,也需要和它们要监测的网络与服务一样云原生、支持编排且自动化。


